

Exploring the Efficiency of Merge Sort: Concurrency vs. Traditional Approach
Comparing Performance in Java's Merge Sort Algorithm


Introduction
In the realm of programming, sorting algorithms play a crucial role in organizing data efficiently. Traditional sorting algorithms like Merge Sort have been extensively studied and optimized for single-threaded execution. However, with the rise of multi-core processors, leveraging concurrency becomes essential for maximizing performance.
In this article, I'll delve into the world of sorting algorithms in Java, specifically Merge Sort, comparing it's traditional implementation with it's concurrent counterpart, and examining how it fares with small and large datasets.
Understanding Traditional Merge Sort Algorithm
Merge Sort is a divide-and-conquer algorithm that works by dividing the input array into smaller sub-arrays, sorting each sub-array recursively, and then merging the sorted sub-arrays to produce a final sorted array. The process is as follows:
Divide: The array is recursively divided into two halves until each sub-array contains only one element. This is achieved by calculating the middle index of the array and recursively calling Merge Sort on the left and right halves.
Conquer: Once the sub-arrays contain only one element, the merge function is called to merge adjacent sub-arrays while maintaining the sorted order
Merge: The merge function combines two sorted sub-arrays into a single sorted array. It does this by comparing elements from each sub-array and selecting the smaller (or larger) element to place into the final merged array.
The following code shows an implementation of MergeSort. It's Time Complexity is: O(n log n) and Space Complexity is: O(n)
private static void merge(int[] array, int start, int mid, int end) {
int[] leftArray = Arrays.copyOfRange(array, start, mid);
int[] rightArray = Arrays.copyOfRange(array, mid, end);
int leftIndex = 0, rightIndex = 0, arrayIndex = start;
while (leftIndex < leftArray.length && rightIndex < rightArray.length) {
if (leftArray[leftIndex] <= rightArray[rightIndex]) {
array[arrayIndex++] = leftArray[leftIndex++];
} else {
array[arrayIndex++] = rightArray[rightIndex++];
}
}
while (leftIndex < leftArray.length) {
array[arrayIndex++] = leftArray[leftIndex++];
}
while (rightIndex < rightArray.length) {
array[arrayIndex++] = rightArray[rightIndex++];
}
}
private static void mergeSort(int[] array, int start, int end) {
if (end - start < 2) {
return;
}
int mid = (start + end) / 2;
mergeSort(array, start, mid);
mergeSort(array, mid, end);
merge(array, start, mid, end);
}
Concurrent Programming
Concurrent programming in Java involves the execution of multiple tasks simultaneously, allowing for better utilization of system resources and improved performance. Key components of concurrent programming in Java include:
Threads: The smallest unit of execution within a process. Java provides built-in support for creating and managing threads through the
Threadclass or by implementing theRunnableinterface.Executors: Provide more flexibility and control over thread management.
Concurrency Utilities: Java offers us synchronized blocks, locks, atomic variables and high-level constructs like
CountDownLatch,Semaphorefor coordinating concurrent tasks.
Benefits of Concurrency in Sorting Algorithms
Concurrency can offer several advantages when applied to sorting algorithms, particularly for handling large datasets:
Parallelism: Concurrent sorting algorithms can leverage multiple threads to process different parts of the dataset simultaneously. This parallelism can lead to significant performance improvements.
Scalability: Concurrency allows sorting algorithms to scale efficiently with increasing dataset sizes by distributing the workload across multiple threads.
Concurrent Merge Sort Algorithm
The difference of both algorithms is that here we split the original array into segments to achieve parallelism. Each segment is sorted concurrently by using mergeSort() then merged into one big array.
I am using a custom ThreadPool which starts a specific number of threads(2, 4, 8, etc) that wait for tasks to be submitted. The CountDownLatch helps us coordinate the completion of sorting tasks performed by multiple threads. When the array is divided into segments, we want to wait until all sorting tasks are completed before merging. The CountDownLatch provides a simple way to achieve this coordination.
public static void concurrentMergeSort(int[] array, ThreadPool threadPool) {
int length = array.length;
int numThreads = threadPool.getNumThreads();
CountDownLatch latch = new CountDownLatch(numThreads);
// Divide the array into segments based on the number of threads
int segmentSize = (int) Math.ceil((double) length / numThreads);
for (int i = 0; i < numThreads; i++) {
int start = i * segmentSize;
int end = Math.min(start + segmentSize, length);
final int segmentStart = start;
final int segmentEnd = end;
threadPool.submitTask(() -> {
mergeSort(array, segmentStart, segmentEnd); // Sorting the segment
latch.countDown();
});
}
try {
latch.await(); // Wait for all sorting tasks to complete
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// Merge sorted segments until only one segment remains
int interval = segmentSize;
while (interval < length) {
for (int i = 0; i < length; i += 2 * interval) {
int start = i;
int mid = i + interval;
int end = Math.min(i + 2 * interval, length);
merge(array, start, mid, end);
}
interval *= 2;
}
}
This custom implementation of ThreadPool uses an ExecutorService that starts as many Threads as needed depending on the number of Tasks inside our BlockingQueue, up to numThreads Threads.
taskQueue.take() calls until a task becomes available in the queue. Once a task is available, the thread will retrieve it from the queue and execute it. This ensures that worker threads are only active when there are tasks to be executed, preventing them from blocking indefinitely when the queue is empty.
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
public class ThreadPool {
private final int numThreads;
private final ExecutorService executor;
private final BlockingQueue<Runnable> taskQueue;
private volatile boolean running;
public ThreadPool(int numThreads){
this.numThreads = numThreads;
executor = Executors.newFixedThreadPool(this.numThreads);
taskQueue = new LinkedBlockingQueue<>();
running = true;
// Start worker threads
for (int i = 0; i < numThreads; i++){
executor.execute(this::workerLoop);
}
}
private void workerLoop(){
while (running){
try {
Runnable task = taskQueue.take();
try{
task.run();
} catch(RuntimeException e){
handleException(e);
}
}
catch (InterruptedException e){
Thread.currentThread().interrupt();
break;
}
}
}
private void handleException(Exception e){
e.printStackTrace();
}
public void submitTask(Runnable task){
try {
taskQueue.put(task);
} catch (InterruptedException e){
Thread.currentThread().interrupt();
}
}
public void shutdown(){
running = false;
executor.shutdown();
}
public int getNumThreads(){
return numThreads;
}
}
Runtime Performance Analysis
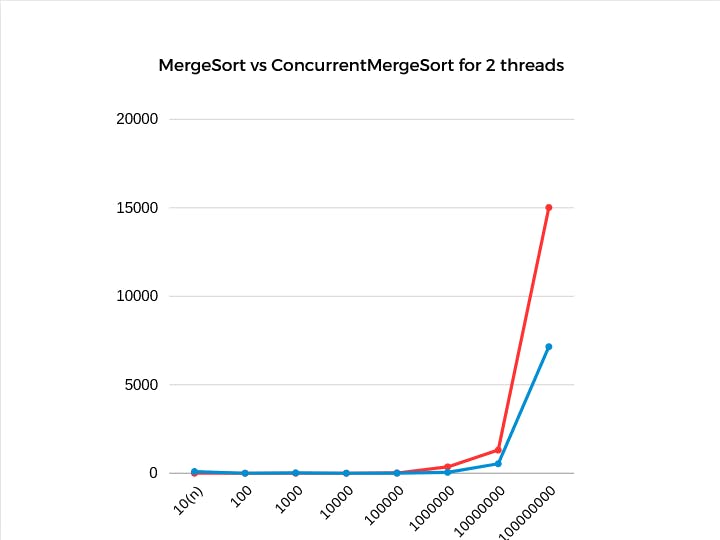
The tests I performed for data up to 1 billion numbers show that on multi-core systems the processing is faster, thus we were able to utilize multi-threading and concurrency to achieve better performance.
Merge Sort is red and it's concurrent version is blue. The numbers on the left are the execution time in ms, and on the bottom we have the number of elements that were sorted. For 2 threads, we achieved approx 2.1x faster execution time(7150ms vs 15017ms).
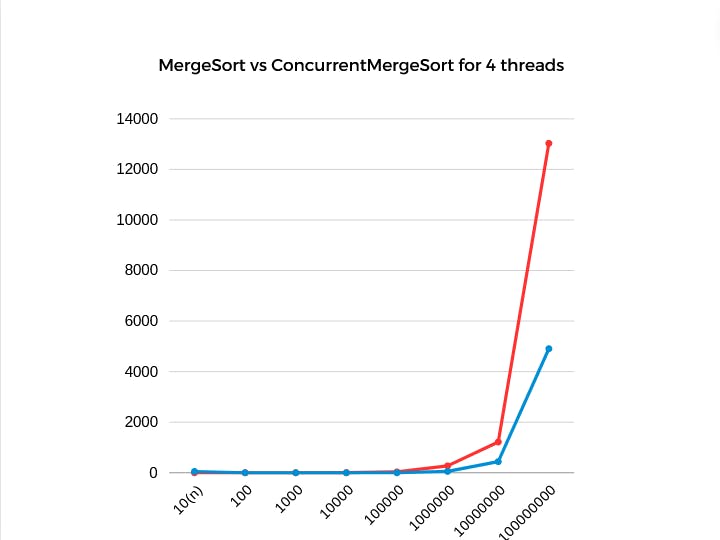
When using 4 threads simultaneously, we achieved a 2.65x speedup(4906ms vs 13030ms).
Conclusion
Our exploration into Merge Sort, has showed us the significant impact of concurrency in improving performance and scalability. By comparing sequential and concurrent implementations, we've observed notable differences in runtime efficiency, particularly when handling large datasets.
Sequential implementations, while straightforward, can become bottle-necked when confronted with sizable datasets due to their inability to fully leverage the available computational resources. On the other hand, concurrent implementations use the power of parallelism, distributing the workload across multiple threads and substantially reducing processing time.
Although there are built-in functionalities in Java for concurrent sorting that may be faster such as ForkJoinPool and Arrays.parallelSort() , this article went to show how parallelism works in detail and it’s implementation for MergeSort.
In the field of software development, understanding the nuances of concurrency becomes increasingly crucial when dealing with performance-critical applications.
By using concurrency, we allow ourselves to build robust, scalable, and high-performance. However, it's essential to recognize that concurrency introduces its own set of challenges. Careful design and optimization are necessary to reap the benefits of concurrency effectively.